提示!本文章仅供学习交流,严禁用于非法用途,文章如有不当可联系本人删除!
一. 目标网站
- aHR0cHM6Ly9kdW4uMTYzLmNvbS90cmlhbC9zcGFjZS1pbmZlcmVuY2U=
二. 准备工作
- 已经安装好的cuda环境,笔者这里的环境是CUDA11.4+cudnn-8.2.2.26,win10环境
- 训练工具:yolov5-7.0 https://github.com/ultralytics/yolov5/releases/tag/v7.0
验证码原图下载:去目标网站上下载1000张左右去重后的原图
- 这里我觉得有必要说一下,去重,去重,去重,重要的事情说三遍,不去重会干扰后续数据集的采集与标注
如何去重,很简单,直接计算图片的md5即可

这时候先别急着去下载,因为和图片url一起返回的还有这张图片对应的语义,也就是front字段的内容,例如:

你需要把语义放到图片命名里方便后面收集语义,例如这样的命名方式:
请点击大写Q朝向一样的小写l_计算后的md5值.jpg
三. 分析图片里包含的类别,和语义想要干什么
- 这部分就像上面二级标题说的,分两段讲
3.1) 收集类别
3.1.1 先手动打开几张图片看下大致有哪些


这里我举了两张图片为例子,图片有1.字母(区分大小写),2.数字,3.几何图形,目前发现是这三种大类,至于具体有哪些细分的类,这时候就用到了上面准备工作里收集到的语义了,我们来从文件名里把语义提取,然后去重写到一个文本里看看:

大概是这样的,事实上,上面的语义结果是我收集了2000张图片去重下来的结果,不过这也太乱了,我们给它排序后再来观察下:

这样是不是就清楚多了,由于篇幅有限,两个语义文件我会放在云盘里方便大家参考
关注我的公众号:爬虫45度,后台发送 "空间推理语义收集" 也可获取下载地址
3.1.2) 将类别具体化
经过第二个文本的观察,我们可以基本确认,验证码的类别有:
1.大小写的字母a-zA-z
2.数字0-9
3.圆锥、立方体、圆柱、球 这四种几何图案
3.2) 语义分析
总结完了类别,再来说说这种语义怎么判断,这里我采取的方式是从后往前分析,这里挑选三个典型的不同语义来讲下:
请点击数字8
请点击正向的大写B
请点击数字7颜色一样的小写f3.2.1) 最终的目标位置
最终的目标位置都在语义的最后,例如 "请点击侧向的大写P" 最终目标就是 "大写P"
3.2.2) 最终目标的关联关系
- 第一个,没有关联关系,直接找目标;
- 第二个,最终目标是B,它没有关联关系,但是它有一个特征,"正向",这时候,找正向且大写的B即可;
第三个,目标物是f,它有一个关联关系,或者说对比/参照关系,7,而他们对比的依据是什么?颜色对吧!
既然如此,找到f(可能是一个或多个),找到7(一个或多个),两两比较,f和某一个7颜色一致的即为正确的f。
也许有人会问,对比下来的结果有两组甚至更多符合呢?那你都说如果了,我的回答是,要么你的识别有问题,要么验证码生成的时候出错了(当然这种概率更小)
经过上面三种类型的语义解析,我们顺理成章的可以从中得出更直接的一个结论,验证码图片上的每一个物体,我们都可以人为的给它按照如下方式来定义:
目标物a:
值:a (可能值:a-zA-z、 0-9、 圆锥、立方体、圆柱、球)
颜色:红色 (可能值:红、 黄、 蓝、 绿、 灰)
朝向:侧向 (可能值:正向、侧向)
根据上面的三种去排列组合你就能推断最终的组合类数量了,我这边是645种,因为几何图形中只有正方体才有正向和侧向,其他三种默认只有正向
即:66个值x5颜色x2朝向-3图形没有侧向x5颜色=645个细分类
请注意,上面我对第二和第三个语义分析的时候是不是只说,B,f,而不是大写B,小写f,因为这里字母的值已经区分大小写了,或者说不用再去判断大小写了。
===========================分界线============================
这里我们先记住一个概念:一张图片中每个物体,都被我们标记上三个属性:值+颜色+朝向
具体怎么解析,后面有提到,下面先用数据集将模型训练出来,这是语义解析的前提。
四. 标注工作
4.1) 训练工具
这里选择用yolov5的v7.0版本来训练,而数据集格式采用yolo 格式
4.2) 标注工具
pip install labelImg然后cmd里在运行环境里直接labelImg 命令即可唤出工具界面,
这里要注意下,标注的时候先选择将数据格式设置为yolo
4.3) 如何标注
按照上面3.2.2中对每一个物体的定义,我们可以这样来写标签,例如这个物体

我们就可以定位为红色-侧向-8,符合3.2.2中的定义:
目标物8:
值:8
颜色:红
朝向:侧向因此,你需要新建一个文件夹xxx,在这个文件夹下有两个文件夹 "images" 和 "labels",前者放数据集原图,后者放标完的txt标签
下面是单张图片的标注示例:

4.4) 数据集整理
4.4.1) 准备标签文件
- 当你在
4.3中标完数据集后,将4.3中提到的labels文件夹里的classes.txt拿出来,按顺序放到配置yaml文件里的names下
注意:这里的顺序不能乱,因为names对应的这个list里每一个元素对应的index就是标签文件txt中开头的序号
比如训练的配置文件是这样的:

某张有正向-红-0的txt标签是这样的

配置文件里names的第0个对应的具体内容是正向-红-0,在txt文件中第一行的首个元素也是0,这个0指向的就是names的第0个值正向-红-0
因此,names的值应该以你标注完成那一刻的classes.txt 为准
五. 根据模型输出和语义提示找到最终结果
5.1) 模型训练与加载
5.1.1) 训练
有了上面提到的数据集,就可以开始训练了,这里就不细说训练的过程了
就提一点,训练的时候classes.txt 这个文件别忘了从标签文件夹中删掉,哈哈
5.1.2) 模型加载
这里默认用上面一步训练得到的pt模型加载出验证码图片上每个物体的坐标信息、标签内容以及置信度等信息
import cv2
import torch
import numpy as np
from models.common import DetectMultiBackend
from utils.augmentations import letterbox
from utils.general import (check_img_size, non_max_suppression, scale_boxes)
# 这里不指定device类型默认为cpu
model = DetectMultiBackend('./models/yd_space.pt')
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(640, s=stride) # 640是训练时候设置的图片尺寸
def Images(cv2Img):
img = letterbox(cv2Img, imgsz, stride=stride)[0]
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img)
return img
def locate_space(binary, CONF=0.25, IOU=0.45):
cv2Img = cv2.imdecode(np.array(bytearray(binary), dtype='uint8'), cv2.IMREAD_UNCHANGED)
im0s = cv2Img
img = Images(cv2Img)
img = torch.from_numpy(img).to(model.device)
img = img.half() if model.fp16 else img.float() # uint8 to fp16/32
img /= 255.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
pred = model(img, augment=False, visualize=False)[0]
pred = non_max_suppression(pred, CONF, IOU, classes=None, agnostic=False)
results = []
for i, det in enumerate(pred):
im0 = im0s
if det is not None and len(det):
det[:, :4] = scale_boxes(img.shape[2:], det[:, :4], im0.shape).round()
for *xyxy, conf, cls in reversed(det):
_list = [int(xyxy[0]), int(xyxy[1]), int(xyxy[2]), int(xyxy[3])]
coord = [int((_list[0] + _list[2]) / 2), int((_list[1] + _list[3]) / 2)]
results.append({'content': names[int(cls)], 'location': _list, 'coord': coord})
return results
with open('123.jpg', 'wb') as f:
binary = f.read()
res = locate_space(binary)
print(res)这部分代码是根据detect.py从各个模块里提纯出来的,仅作参考,你也可以根据需求添加自己需要的一些功能
5.2) 语义拆分与目标确认
5.2.1) 优化模型的输出结果
根据上面
5.1.2的输出结果,大概是这样的,分别是类别,x1y1x2y2,中心点的坐标[ {'content': '正向-黄-l', 'location': [197, 72, 214, 122], 'coord': [205, 97]}, {'content': '侧向-黄-L', 'location': [109, 75, 143, 122], 'coord': [126, 98]}, {'content': '正向-灰-4', 'location': [181, 22, 225, 71], 'coord': [203, 46]}, {'content': '正向-红-F', 'location': [49, 58, 85, 107], 'coord': [67, 82]}, {'content': '侧向-黄-F', 'location': [23, 24, 58, 71], 'coord': [40, 47]}, {'content': '正向-蓝-L', 'location': [81, 26, 121, 76], 'coord': [101, 51]}, {'content': '侧向-灰-P', 'location': [241, 88, 280, 137], 'coord': [260, 112]} ]这样还不够清晰,我们对locate_space方法修改下可以得到这样的结果
orientation--朝向
color--颜色
cont--本身的值
coord--最终结果的中心点坐标
[ {'orientation': '正向', 'color': '黄', 'cont': 'l', 'coord': [{'x': 205, 'y': 97}]}, {'orientation': '侧向', 'color': '黄', 'cont': 'L', 'coord': [{'x': 126, 'y': 98}]}, {'orientation': '正向', 'color': '灰', 'cont': '4', 'coord': [{'x': 203, 'y': 46}]}, {'orientation': '正向', 'color': '红', 'cont': 'F', 'coord': [{'x': 67, 'y': 82}]}, {'orientation': '侧向', 'color': '黄', 'cont': 'F', 'coord': [{'x': 40, 'y': 47}]}, {'orientation': '正向', 'color': '蓝', 'cont': 'L', 'coord': [{'x': 101, 'y': 51}]}, {'orientation': '侧向', 'color': '灰', 'cont': 'P', 'coord': [{'x': 260, 'y':112}]} ]这里直接将三个属性拆分成单独的字段,为语义解析做准备
重新修改部分的代码:
def locate_space(binary, CONF=0.25, IOU=0.45): cv2Img = cv2.imdecode(np.array(bytearray(binary), dtype='uint8'), cv2.IMREAD_UNCHANGED) im0s = cv2Img img = Images(cv2Img) img = torch.from_numpy(img).to(model.device) img = img.half() if model.fp16 else img.float() # uint8 to fp16/32 img /= 255.0 if len(im.shape) == 3: im = im[None] # expand for batch dim pred = model(img, augment=False, visualize=False)[0] pred = non_max_suppression(pred, CONF, IOU, classes=None, agnostic=False) new_data = [] for i, det in enumerate(pred): im0 = im0s if det is not None and len(det): det[:, :4] = scale_boxes(img.shape[2:], det[:, :4], im0.shape).round() for *xyxy, conf, cls in reversed(det): _list = [int(xyxy[0]), int(xyxy[1]), int(xyxy[2]), int(xyxy[3])] coord = [int((_list[0] + _list[2]) / 2), int((_list[1] + _list[3]) / 2)] content = names[int(cls)].split('-') new_data.append({'orientation': content[0], 'color': content[1], 'cont': content[2], 'coord': [{'x': coord[0], 'y': coord[1]}]}) return new_data
5.2.2) 语序解析
这里我是用正则提取的,new_data 就是上面5.2.1中第二个代码块的格式,大体思路如下图所示:

六. 测试与总结
6.1) 测试
- 这里小测500次,错了3次,正确率99.4%

本次模型cpu(i7-11800H)推理单并发下的速度为110ms上下,13900KF下是75ms左右

6.2) 错误分析
上面的测试中错了3次,因为在测试的时候我把错误的图片保存下来了,来看下错在哪(毕竟谁不想正确率100%呢,狗头保命)
错误的图片有以下三张,语义我也一起收集了,如下
请点击立方体朝向一样的大写E_165e63af0c424010b438ac80e00d43a6.jpg
请点击黄色立方体朝向一样的大写O_bed10708dddc476f8ecad3eaf3ecaf98.jpg
请点击立方体朝向一样的小写b_9067c5afbce4496f89726a88d33f5b36.jpg然后我去用识别代码把目标画出来

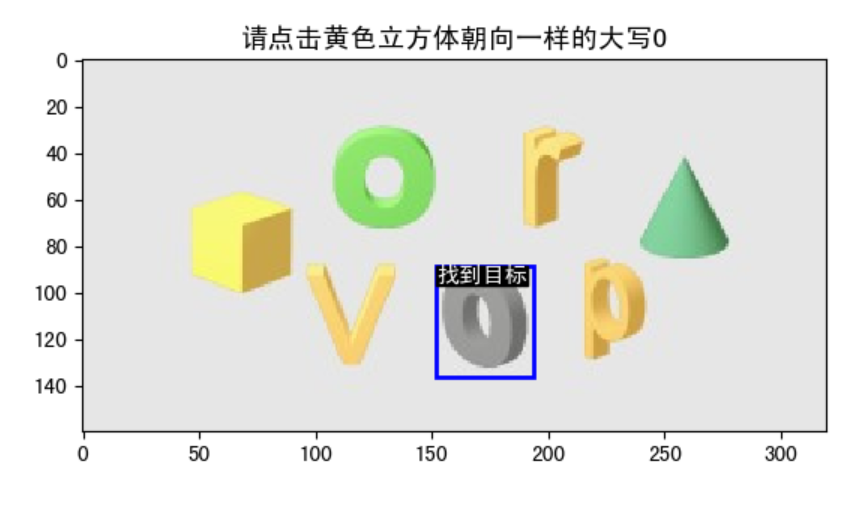
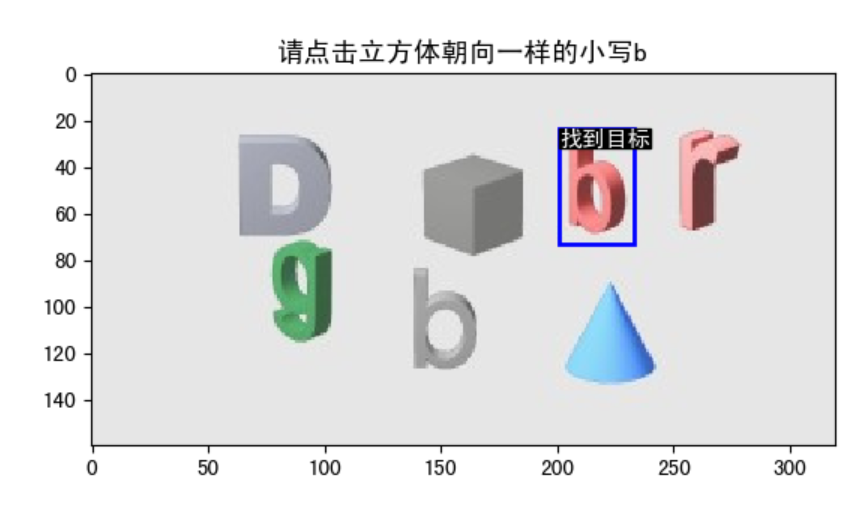
好像都对的啊,淦
经过观察我总结了下,错误的图片有以下语义特征:包含立方体朝向一样 这几个关键字,而且都是侧向的,如果立方体朝向是正向的就能拿到validate,也许是验证码的问题。
后续补充:又验证了1000次仍然是这种情况明明识别正确但验证错误...
要改的话也简单,直接在语义里面判断下就行了。这里就不多赘述了。
6.3) 总结
某盾的空间推理难点我个人觉得在于标注,首先细分类很多(645个),其次某些字母的大小写真的caodan
其他的空间推理例如某验三代的,某美,某音,某讯防水墙的等等,按照我上面的思路都是可行的,感兴趣的小伙伴快动起手来吧
最后,感谢我向北哥哥的帮助。
至此,完结,撒花~
